API¶
python-recsys: A simple python recommender system
Algorithms¶
See some usage examples here
Baseclass¶
- class recsys.algorithm.baseclass.Algorithm¶
Base class Algorithm
It has the basic methods to load a dataset, get the matrix and the raw input data, add more data (tuples), etc.
Any other Algorithm derives from this base class
- add_tuple(tuple)¶
Add a tuple in the dataset
Parameters: - tuple – a tuple containing <rating, user, item> information. Or, more general: <value, row, col>
- get_data()¶
Returns: An instance of Data class. The raw dataset (input for matrix M).
- get_matrix()¶
Returns: matrix M
- get_matrix_similarity()¶
Returns: the self-similarity matrix
- kmeans(id, k=5, is_row=True)¶
K-means clustering. http://en.wikipedia.org/wiki/K-means_clustering
Clusterizes the (cols) values of a given row, or viceversa
Parameters: - id – row (or col) id to cluster its values
- k – number of clusters
- is_row (Boolean) – is param id a row (or a col)?
- load_data(filename, force=True, sep='t', format={'col': 2, 'value': 0, 'row': 1}, pickle=False)¶
Loads a dataset file
See params definition in datamodel.Data.load()
- save_data(filename, pickle=False)¶
Saves the dataset in divisi2 matrix format (i.e: value <tab> row <tab> col)
Parameters: - filename (boolean) – file to store the data
- pickle – save in pickle format?
- set_data(data)¶
Sets the raw dataset (input for matrix M)
Parameters: - data (Data) – a Dataset class (list of tuples <value, row, col>)
- similar(i, n=10)¶
Parameters: - i (user or item id) – a row in M
- n (int) – number of similar elements
Returns: the most similar elements of i
- similarity(i, j)¶
Parameters: - i (user or item id) – a row in M
- j (user or item id) – a row in M
Returns: the similarity between the two elements i and j
SVD¶
- class recsys.algorithm.factorize.SVD(filename=None)¶
Inherits from base class Algorithm. It computes SVD (Singular Value Decomposition) on a matrix M
It also provides recommendations and predictions using the reconstructed matrix M’
Parameters: - filename (string) – Path to a Zip file, containing an already computed SVD (U, Sigma, and V) for a matrix M
- compute(k=100, min_values=None, pre_normalize=None, mean_center=False, post_normalize=True, savefile=None)¶
Computes SVD on matrix M,
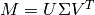
Parameters: - k (int) – number of dimensions
- min_values (int) – min. number of non-zeros (or non-empty values) any row or col must have
- pre_normalize (string) – normalize input matrix. Possible values are tfidf, rows, cols, all.
- mean_center (Boolean) – centering the input matrix (aka mean substraction)
- post_normalize (Boolean) – Normalize every row of
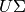 to be a unit vector. Thus, row similarity (using cosine distance) returns
to be a unit vector. Thus, row similarity (using cosine distance) returns ![[-1.0 .. 1.0]](_images/math/24323325974c3d0f493c95a63f6818fb012d7b0c.png)
- savefile (string) – path to save the SVD factorization (U, Sigma and V matrices)
- kmeans(ids, k=5, components=3, are_rows=True)¶
K-means clustering. It uses k-means++ (http://en.wikipedia.org/wiki/K-means%2B%2B) to choose the initial centroids of the clusters
Clusterizes a list of IDs (either row or cols)
Parameters: - ids – list of row (or col) ids to cluster
- k – number of clusters
- components – how many eigen values use (from SVD)
- are_rows (Boolean) – is param ids a list of rows (or cols)?
- load_model(filename)¶
Loads SVD transformation (U, Sigma and V matrices) from a ZIP file
Parameters: - filename (string) – path to the SVD matrix transformation (a ZIP file)
- predict(i, j, MIN_VALUE=None, MAX_VALUE=None)¶
Predicts the value of
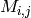 , using reconstructed matrix
, using reconstructed matrix 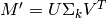
Parameters:
- recommend(i, n=10, only_unknowns=False, is_row=True)¶
Recommends items to a user (or users to an item) using reconstructed matrix
E.g. if i is a row and only_unknowns is True, it returns the higher values of
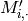
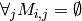
Parameters: - i (user or item id) – row or col in M
- n (int) – number of recommendations to return
- only_unknowns (Boolean) – only return unknown values in M? (e.g. items not rated by the user)
- is_row (Boolean) – is param i a row (or a col)?
- save_model(filename, options={})¶
Saves SVD transformation (U, Sigma and V matrices) to a ZIP file
Parameters:
SVD Neighbourhood¶
- class recsys.algorithm.factorize.SVDNeighbourhood(filename=None, Sk=10)¶
Classic Neighbourhood plus Singular Value Decomposition. Inherits from SVD class
Predicts the value of
, using simple avg. (weighted) of
all the ratings by the most similar users (or items). This similarity, sim(i,j) is derived from the SVDParameters: - predict(i, j, Sk=10, weighted=True, MIN_VALUE=None, MAX_VALUE=None)¶
Predicts the value of
, using simple avg. (weighted) of
all the ratings by the most similar users (or items)- if weighted:
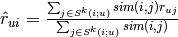
- else:
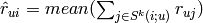
Parameters: - i (user or item id) – row in M,
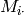
- j (item or user id) – col in M,
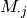
- Sk (int) – number of k elements to be used in
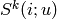
- weighted (Boolean) – compute avg. weighted of all the ratings?
- MIN_VALUE (float) – min. value in M (e.g. in ratings[1..5] => 1)
- MAX_VALUE (float) – max. value in M (e.g. in ratings[1..5] => 5)
Evaluation¶
See some examples
- class recsys.evaluation.baseclass.Evaluation(data=None)¶
Base class for Evaluation
It has the basic methods to load ground truth and test data. Any other Evaluation class derives from this base class.
Parameters: - data (list) – A list of tuples, containing the real and the predicted value. E.g: [(3, 2.3), (1, 0.9), (5, 4.9), (2, 0.9), (3, 1.5)]
- add(rating, rating_pred)¶
Adds a tuple <real rating, pred. rating>
Parameters: - rating – a real rating value (the ground truth)
- rating_pred – the predicted rating
- add_test(rating_pred)¶
Adds a predicted rating to the current test list
Parameters: - rating_pred – the predicted rating
- compute()¶
Computes the evaluation using the loaded ground truth and test lists
- get_ground_truth()¶
Returns: the ground truth list
- get_test()¶
Returns: the test dataset (a list)
- load(ground_truth, test)¶
Loads both the ground truth and the test lists. The two lists must have the same length.
Parameters:
Data Model¶
pyrecsys data model includes: users, items, and its interaction. See some datamodel examples
Item¶
- class recsys.datamodel.item.Item(id)¶
An item, with its related metadata information
Parameters: - id (string or int) – item id
Returns: an item instance
- add_data(data)¶
Parameters: - data (dict() or list()) – associated data for the item
- get_data()¶
Returns the associated information of the item
- get_id()¶
Returns the Item id
User¶
- class recsys.datamodel.user.User(id)¶
User information, including her interaction with the items
Parameters: - id (string or int) – user id
Returns: a user instance
- add_item(item_id, weight)¶
Parameters: - item_id – An item ID
- weight – The weight (rating, views, plays, etc.) of the item_id for this user
- get_id()¶
Returns the User id
- get_items()¶
Returns the list of items for the user
Data¶
- class recsys.datamodel.data.Data¶
Handles the relationshops among users and items
- add_tuple(tuple)¶
Parameters: - tuple – a tuple containing <rating, user, item> information (e.g. <value, row, col>)
- get()¶
Returns: a list of tuples
- load(path, force=True, sep='t', format=None, pickle=False)¶
Loads data from a file
Parameters: - path (string) – filename
- force (Boolean) – Cleans already added data
- sep (string) – Separator among the fields of the file content
- format (dict()) – Format of the file content. Default format is ‘value’: 0 (first field), then ‘row’: 1, and ‘col’: 2. E.g: format={‘row’:0, ‘col’:1, ‘value’:2}. The row is in position 0, then there is the column value, and finally the rating. So, it resembles to a matrix in plain format
- pickle (Boolean) – is input file in pickle format?
- save(path, pickle=False)¶
Saves data in output file
Parameters: - path – output filename
- pickle (Boolean) – save in pickle format?