Examples¶
You can find all these examples in the ./draft folder.
Movielens¶
import sys
#To show some messages:
import recsys.algorithm
recsys.algorithm.VERBOSE = True
from recsys.algorithm.factorize import SVD
from recsys.datamodel.data import Data
from recsys.evaluation.prediction import RMSE, MAE
#Dataset
PERCENT_TRAIN = int(sys.argv[2])
data = Data()
data.load(sys.argv[1], sep='::', format={'col':0, 'row':1, 'value':2, 'ids':int})
# About format parameter:
# 'row': 1 -> Rows in matrix come from column 1 in ratings.dat file
# 'col': 0 -> Cols in matrix come from column 0 in ratings.dat file
# 'value': 2 -> Values (Mij) in matrix come from column 2 in ratings.dat file
# 'ids': int -> Ids (row and col ids) are integers (not strings)
#Train & Test data
train, test = data.split_train_test(percent=PERCENT_TRAIN)
#Create SVD
K=100
svd = SVD()
svd.set_data(train)
svd.compute(k=K, min_values=5, pre_normalize=None, mean_center=True, post_normalize=True)
#Evaluation using prediction-based metrics
rmse = RMSE()
mae = MAE()
for rating, item_id, user_id in test.get():
try:
pred_rating = svd.predict(item_id, user_id)
rmse.add(rating, pred_rating)
mae.add(rating, pred_rating)
except KeyError:
continue
print 'RMSE=%s' % rmse.compute()
print 'MAE=%s' % mae.compute()
Save it as movielens.py, and run it!
$ python movielens.py tests/data/movielens/ratings.dat 80
# Here's the output:
Creating matrix
Updating matrix: squish to at least 5 values
Computing svd k=100, min_values=5, pre_normalize=None, mean_center=True, post_normalize=True
RMSE=0.91919
MAE=0.717771
Last.fm¶
Why is Ringo always forgotten?
- (Slow) Get the last.fm 360K dataset, and save it to /tmp:
cd /tmp/
wget http://mtg.upf.edu/static/datasets/last.fm/lastfm-dataset-360K.tar.gz
tar xvzf lastfm-dataset-360K.tar.gz
- (Faster way) Download this tar file that already contains the matrix.dat (~17M lines), and copy the 3 files to /tmp
cd /tmp/
wget http://www.dtic.upf.edu/~ocelma/MusicRecommendationDataset/lastfm360K-svd-example.tar.gz
tar xvzf lastfm360K-svd-example.tar.gz
and then just copy these 10 lines of code!
import sys
import recsys.algorithm
recsys.algorithm.VERBOSE = True
from recsys.utils.svdlibc import SVDLIBC
# 1. (Slow) Create Sparse matrix.dat SVDLIBC input (http://tedlab.mit.edu/~dr/SVDLIBC/SVD_F_ST.html).
# This eats quite a lot of memory! (~9Gb)
#svdlibc = SVDLIBC(datafile='/tmp/lastfm-dataset-360K/usersha1-artmbid-artname-plays.tsv',
# matrix='/tmp/matrix.dat', prefix='/tmp/svd')
#svdlibc.to_sparse_matrix(sep='\t', format={'col':0, 'row':1, 'value':3})
# 2. (Faster way):
# You already downloaded and copied these 3 files at /tmp :
# /tmp/matrix.dat
# /tmp/svd.ids.rows
# /tmp/svd.ids.cols
svdlibc = SVDLIBC()
# Compute SVDLIBC
k = 100
svdlibc.compute(k, matrix='/tmp/matrix.dat', prefix='/tmp/svd') # Wait ~2 mins.
svd = svdlibc.export() # This can consume ~2.8Gb. of memory
# print svd
ID = 'b10bbbfc-cf9e-42e0-be17-e2c3e1d2600d' # The Beatles MBID
svd.similar(ID) # Get artists similar to The Beatles (...why is Ringo always forgotten!?)
[('b10bbbfc-cf9e-42e0-be17-e2c3e1d2600d', 0.99999999999999978), # The Beatles
('4d5447d7-c61c-4120-ba1b-d7f471d385b9', 0.96963526974942182), # John Lennon
('31f49c01-b8e0-40ba-b1aa-3754f6fa78d5', 0.96566802153067377), # Paul McCartney & Wings
('5c014631-875c-4f3e-89e9-22cf9d4769a4', 0.9554322804979507), # John Lennon & Yoko Ono
('ba550d0e-adac-4864-b88b-407cab5e76af', 0.95520067803777453), # Paul McCartney
('e975f847-7b7a-4313-8ebc-1cbfc978e817', 0.95385390155825112), # Paul & Linda McCartney
('42a8f507-8412-4611-854f-926571049fa0', 0.94022861823264092), # George Harrison
('5235052b-7fa0-498b-accf-26b9e7767da7', 0.93691208464079334), # Mohamed Moneir
('dafcd725-9cb6-4347-be21-fd9a950e8064', 0.9352608795525883), # Klaatu
('cb56afea-5648-4173-b1b7-762288492997', 0.93383747203947887)] # Bobby Sherman
The Beatles similar artists’ are so so... Still, you can easily improve these results as explained in this boring book
Implementing a new algorithm¶
Now, here’s an example about how to create a new algorithm, by extending BaseClass algorithm class.
This Baseline dummy algorithm returns the avg. rating of a user, when predicting the value 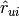 , for user
, for user  and any item
and any item 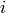
from numpy import mean
from operator import itemgetter
from recsys.algorithm.baseclass import Algorithm
class Baseline(Algorithm):
def __init__(self):
#Call parent constructor
super(Baseline, self).__init__()
# 'Cache' for user avg. rating
self._user_avg_rating = dict()
def predict(self, i, j, MIN_VALUE=None, MAX_VALUE=None, user_is_row=True):
index = i
if not user_is_row:
index = j
if not self._user_avg_rating.has_key(index):
if user_is_row:
vector = self.get_matrix().get_row(index).entries()
else:
vector = self.get_matrix().get_col(index).entries()
# Vector is a list of tuples: (rating, pos). E.g (3.0, 20)
self._user_avg_rating[index] = mean(map(itemgetter(0), vector))
predicted_value = self._user_avg_rating[index]
if MIN_VALUE:
predicted_value = max(predicted_value, MIN_VALUE)
if MAX_VALUE:
predicted_value = min(predicted_value, MAX_VALUE)
return predicted_value
Save this example as baseline.py
Here’s an example using this simple baseline Algorithm class:
import sys
#To show some messages:
import recsys.algorithm
recsys.algorithm.VERBOSE = True
from recsys.evaluation.prediction import RMSE, MAE
from recsys.datamodel.data import Data
from baseline import Baseline #Import the test class we've just created
#Dataset
PERCENT_TRAIN = int(sys.argv[2])
data = Data()
data.load(sys.argv[1], sep='::', format={'col':0, 'row':1, 'value':2})
#Train & Test data
train, test = data.split_train_test(percent=PERCENT_TRAIN)
baseline = Baseline()
baseline.set_data(train)
baseline.compute() # In this case, it does nothing
# Evaluate
rmse = RMSE()
mae = MAE()
for rating, item_id, user_id in test.get():
try:
pred_rating = baseline.predict(item_id, user_id, user_is_row=False)
rmse.add(rating, pred_rating)
mae.add(rating, pred_rating)
except KeyError:
continue
print 'RMSE=%s' % rmse.compute()
print 'MAE=%s' % mae.compute()
Save this example as test_baseline.py
And run it:
$ python test_baseline.py tests/data/movielens/ratings.dat 80
# Here's the output:
Loading dataset tests/data/movielens/ratings.dat
Creating matrix
RMSE=1.033579
MAE=0.827535