Quick start¶
Once you’ve built and installed pyrecsys, you can:
Set VERBOSE mode, to see some messages:
>>> import recsys.algorithm >>> recsys.algorithm.VERBOSE = True
Load a dataset (first download the Movielens 1M Ratings Data Set, ratings.dat file):
>>> from recsys.algorithm.factorize import SVD >>> svd = SVD() >>> svd.load_data(filename='./data/movielens/ratings.dat', sep='::', format={'col':0, 'row':1, 'value':2, 'ids': int}) Loading ./data/movielens/ratings.dat ..........|
Compute SVD,
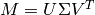 :
:>>> k = 100 >>> svd.compute(k=k, min_values=10, pre_normalize=None, mean_center=True, post_normalize=True) Creating matrix (1000209 tuples) Matrix density is: 4.4684% Updating matrix: squish to at least 10 values Computing svd k=100, min_values=10, pre_normalize=None, mean_center=True, post_normalize=True
you can also save the output SVD model (in a zip file):
>>> k = 100 >>> svd.compute(k=k, min_values=10, pre_normalize=None, mean_center=True, post_normalize=True, savefile='/tmp/movielens') Creating matrix (1000209 tuples) Matrix density is: 4.4684% Updating matrix: squish to at least 10 values Computing svd k=100, min_values=10, pre_normalize=None, mean_center=True, post_normalize=True Saving svd model to /tmp/movielensNote
For more information about svd.compute() parameters see Algorithms section.
once the SVD model has been saved (to a zip file) you can load it anytime, thus there’s not need to svd.compute() it again:
>>> from recsys.algorithm.factorize import SVD >>> svd2 = SVD(filename='/tmp/movielens') # Loading already computed SVD model >>> # Get two movies, and compute its similarity: >>> ITEMID1 = 1 # Toy Story (1995) >>> ITEMID2 = 2355 # A bug's life (1998) >>> svd2.similarity(ITEMID1, ITEMID2) 0.67706936677315799
Compute similarity between two movies
>>> ITEMID1 = 1 # Toy Story (1995) >>> ITEMID2 = 2355 # A bug's life (1998) >>> svd.similarity(ITEMID1, ITEMID2) 0.67706936677315799
Get movies similar to Toy Story:
>>> svd.similar(ITEMID1) [(1, 0.99999999999999978), # Toy Story (3114, 0.87060391051018071), # Toy Story 2 (2355, 0.67706936677315799), # A bug's life (588, 0.5807351496754426), # Aladdin (595, 0.46031829709743477), # Beauty and the Beast (1907, 0.44589398718134365), # Mulan (364, 0.42908159895574161), # The Lion King (2081, 0.42566581277820803), # The Little Mermaid (3396, 0.42474056361935913), # The Muppet Movie (2761, 0.40439361857585354)] # The Iron Giant
Predict rating for a given user and movie,
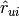
>>> MIN_RATING = 0.0 >>> MAX_RATING = 5.0 >>> ITEMID = 1 >>> USERID = 1 >>> svd.predict(ITEMID, USERID, MIN_RATING, MAX_RATING) 5.0 #Predicted value >>> svd.get_matrix().value(ITEMID, USERID) 5.0 #Real value
Recommend (non–rated) movies to a user:
>>> svd.recommend(USERID, is_row=False) #cols are users and rows are items, thus we set is_row=False [(2905, 5.2133848204673416), # Shaggy D.A., The (318, 5.2052108435956033), # Shawshank Redemption, The (2019, 5.1037438278755474), # Seven Samurai (The Magnificent Seven) (1178, 5.0962756861447023), # Paths of Glory (1957) (904, 5.0771405690055724), # Rear Window (1954) (1250, 5.0744156653222436), # Bridge on the River Kwai, The (858, 5.0650911066862907), # Godfather, The (922, 5.0605327279819408), # Sunset Blvd. (1198, 5.0554543765500419), # Raiders of the Lost Ark (1148, 5.0548789542105332)] # Wrong Trousers, The
Which users should see Toy Story? (e.g. which users -that have not rated Toy Story- would give it a high rating?)
>>> svd.recommend(ITEMID) [(283, 5.716264440514446), (3604, 5.6471765418323141), (5056, 5.6218800339214496), (446, 5.5707524860615738), (3902, 5.5494529168484652), (4634, 5.51643364021289), (3324, 5.5138903299082802), (4801, 5.4947999354188548), (1131, 5.4941438045650068), (2339, 5.4916048051511659)]
For large datasets (say more than 10M tuples), it might be better to run SVDLIBC directly (divisi2 -that also uses SVDLIBC- is way too slow creating the matrix and computing SVD):
>>> from recsys.utils.svdlibc import SVDLIBC >>> svdlibc = SVDLIBC('./data/movielens/ratings.dat') >>> svdlibc.to_sparse_matrix(sep='::', format={'col':0, 'row':1, 'value':2, 'ids': int}) >>> svdlibc.compute(k=100) >>> svd = svdlibc.export() >>> svd.similar(ITEMID1) # results might be different than example 4. as there's no min_values=10 set here [(1, 0.99999999999999978), (3114, 0.84099896392054219), (588, 0.79191433686817747), (2355, 0.7772760704844065), (1265, 0.74946256379033827), (364, 0.73730970556786068), (2321, 0.73652131961235268), (595, 0.71665833726881523), (3253, 0.7075696829413568), (1923, 0.69687698887991523)]